Introduction
Motivation
Computer vision has progressed rapidly in the past few years thanks to the development of machine learning, enabling systems to handle complex tasks, sometimes surpassing human capabilities. However, further development raises two critical problems: high energy consumption and dependence on supervised algorithms, which necessitates large amounts of labeled data for training. These challenges result in high costs associated with utilizing computer vision for complex problems. Hence, there is an urgent need for low-energy and unsupervised models.
Spiking cameras have garnered attention due to their bio-inspired paradigm and low power consumption advantages. Unlike traditional cameras capturing complete images, spiking cameras capture events, representing changes in pixel brightness. This event-based approach significantly reduces memory usage and energy consumption.
Goals
This manuscript presents research on Spiking Neural Network (SNN) for action recognition using spiking cameras, focusing on low energy consumption and unsupervised models. The primary objective is to convert spiking videos into frames directly usable as input for the SNN model developed by our team.
Spiking Camera
Normal Camera
Traditional cameras, whether CMOS sensors, CCD sensors, or RGBD cameras, capture images at a constant frequency, resulting in inherent delays. Motion blur can occur due to object movement within the exposure time. Additionally, normal cameras have a limited dynamic range and capture redundant information for each frame, leading to efficiency issues.
Spiking Camera Overview
A spiking camera, also known as an event camera, captures events comprising a timestamp, pixel coordinates, and polarity, representing changes in brightness. Spiking videos are streams of events captured by spiking cameras, providing an asynchronous and sparse representation of the scene.
Principles of Spiking Camera
- Brightness Change: Spiking cameras output events based on brightness changes, not absolute brightness.
- Threshold: Events are generated when brightness changes reach a certain threshold, an inherent parameter of the camera.
Relationship with SNN
Spiking cameras’ event-based representation aligns well with spiking neural networks (SNNs), which use discrete spikes to transmit information, mimicking biological neural systems. SNNs are energy-efficient and excel at processing spatio-temporal information, making them suitable for tasks involving spiking cameras.
Spiking Dataset
Nature of Spiking Data
Spiking data is an event stream captured by a spiking camera. Each event, denoted as $e_i$, is described by the tuple $[t_i, x_i, y_i, p_i]$, where $i \in {1, 2, 3, 4, \dots, N \times M}$. Here:
- $t_i \geq 0$ is the timestamp of the event.
- $(x_i, y_i) \in {1, 2, \dots, N} \times {1, 2, \dots, M}$ represents the pixel coordinates.
- $p_i \in {-1, 1}$ denotes the polarity, where -1 and 1 represent OFF (brightness decrease) and ON (brightness increase) events, respectively.
- $N$ and $M$ are the dimensions of the pixel grid.
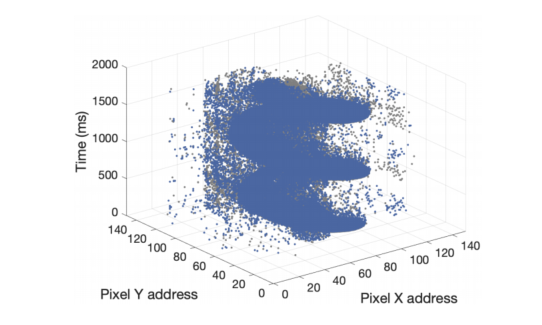
Figure above shows a visualization of a example of spiking video. ON and OFF events are represented in blue and gray, respectively.
List of Spiking Datasets
Various event-based datasets are available, some converted from traditional video datasets, while others are captured by spiking cameras in real scenes.

The Dataset We Chose
We selected the DVS-Gesture dataset for further study. This dataset, created by researchers from the Institute of Neuroinformatics at the University of Zurich and ETH Zurich, comprises 11 hand gestures, including hand clapping, hand waves, forearm rolls, and musical instrument interactions.
Spiking Neural Network
Overview
The traditional artificial neuron model mainly includes two functions, one is to calculate the weighted sum of the signals transmitted by the previous layer of neurons, the other is to use a nonlinear activation function to output signals. The former is used to imitate the way of transmitting information between biological neurons, while the latter is used to improve the nonlinear computing ability of neural networks.
A Spiking neural network is the neural network which is more similar to biological neural network. This third generation networks receive and output data in the form of spikes. Each spike corresponds to a specific weight specified by the synapse it travels across.

Spiking Neuron Model
Spiking neurons model biological neurons, where the membrane potential approaches a threshold value upon receiving spikes. Upon exceeding the threshold, the neuron emits a spike to connected neurons. The simplest form of the spiking neuron model is expressed using an input current $z$ derived from incoming spikes.
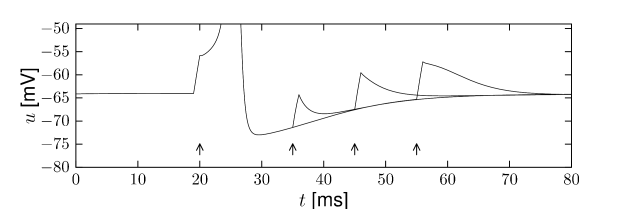
Leaky Integrate and Fire Model
To address the computational complexity of the HH model, simplified models like the Leaky Integrate and Fire (LIF) model have been proposed. The LIF model considers the cell membrane’s electrical properties as a combination of resistance and capacitance, making it closer to biology. It introduces a leak to the membrane potential $v$, allowing neurons to return to the resting state in the absence of activity \cite{falez2019improving}. Additionally, the LIF model accounts for the refractory period after an action potential emission. After emitting an action potential, the neuron remains at a reset potential for several milliseconds.
The LIF model can be expressed as:
$$
\tau_{\text{leak}} \frac{\partial v}{\partial t} = \left[v(t) - v_{\text{rest}}\right] + r_{\mathrm{m}} z(t)
$$
where:
- $T_{\text{leak}} = r_m \cdot c_m$
- $v_{\text{rest}}$ is the reset potential
- $c_m$ is the membrane capacitance
- $r_m$ is the membrane resistance
- $v_{\text{th}}$ is the defined threshold
When $v \geq v_{\text{th}}$, $v$ resets to $v_{\text{rest}}$.
Data Pre-processing
Baseline Spiking Architecture
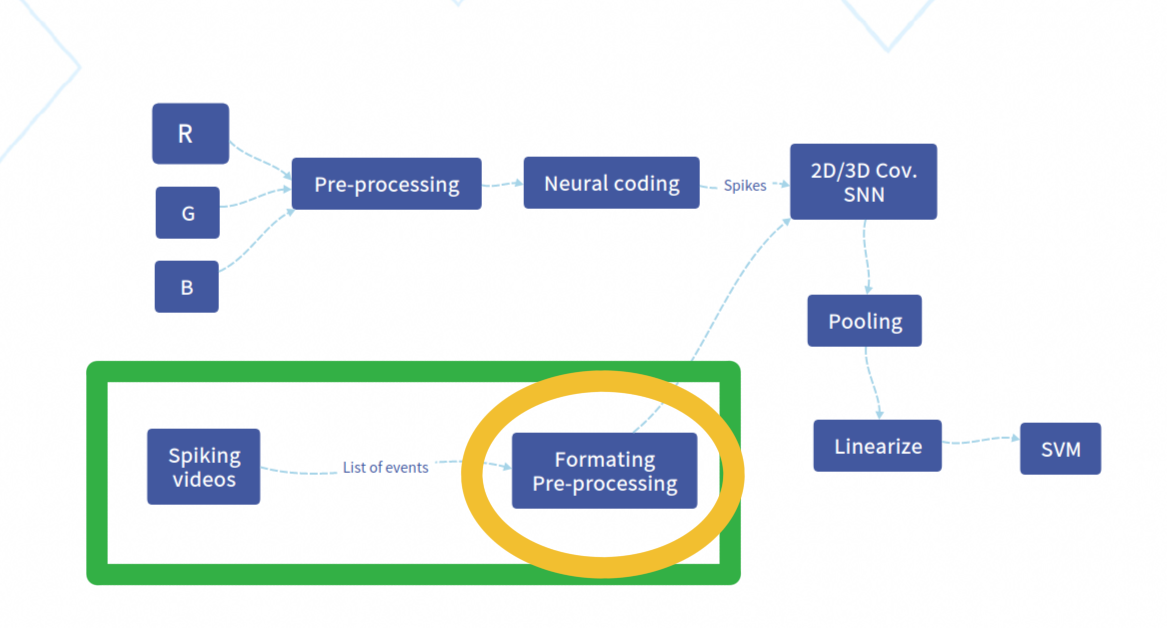
The model receives RGB videos as input, and our goal is to replace this part with spiking videos directly. The baseline spiking architecture is depicted in Figure 5. The green circle represents the part we aim to replace, while the yellow circle indicates the pre-processing step to adapt the input spiking videos to fit into the convolution part of the model.
Explore the DVS-Gesture Dataset
The DVS-Gesture dataset contains 30 binary event stream files, each containing continuous recordings of all 11 classes of gestures. Additionally, for each event stream file, there is a corresponding table containing the start and end timestamps of each category of action.
Convert Events Stream to Frames
The event-to-frame integrating method for pre-processing spiking datasets is widely used.
Integration Events Block into Frame
Denote a two-channel frame as:
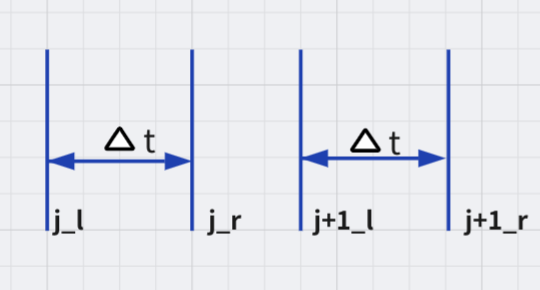
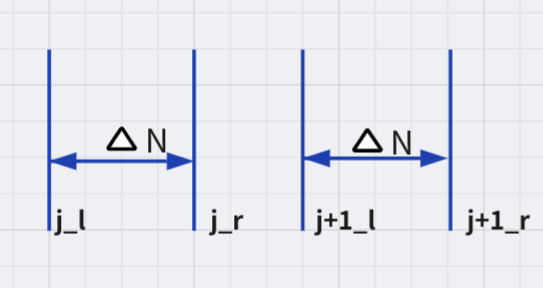
A frame in the frame data after integration noted $F(j)$ and a pixel at $(p, x, y)$ as $F(j, p, x, y)$, the pixel value is integrated from the events data whose indices are in $[j_{l}, j_{r})$:
$$
F(j, p, x, y) = \sum_{i=j_l}^{j_r-1} \mathcal{I}_{p, x, y}(p_i, x_i, y_i)
$$
Where $\mathcal{I}$ is an indicator function and it equals 1 only when $ (p, x, y) = (p_{i}, x_{i}, y_{i}) $.
Split by Fixed Number Frames
The first idea is to split the event stream into a video of a fixed number of frames. In this logic, we can split the event stream equally into event blocks according to the total number of events or the total timestamp interval and then integrate them into frames.
If split method is time, then:
If split method is number, then:
Split by Fixed Duration
The idea of splitting by a fixed number of frames may lead to different speeds of motion in the obtained frames, as different classes of action videos may have different durations. Using a fixed time interval integration is more in line with the actual physical system. For example, integrating every 10 ms gives $\lfloor \frac{L}{10} \rfloor$ frames for data of length $L$ ms. However, the length of each sample in the spiking dataset is often different, resulting in frames of different lengths. We will do zero-padding for the action event stream integrated into frame sequences of the same length.
Experiment
The Input Data Format of the Simulator
The simulator implements the SNN model and receives samples as pairs of sample labels and tensors of action videos in the shape of (FRAME_HEIGHT, FRAME_WIDTH, VIDEO_DEPTH, FRAME_NUMBER).
Results
The Result of the Pre-processing
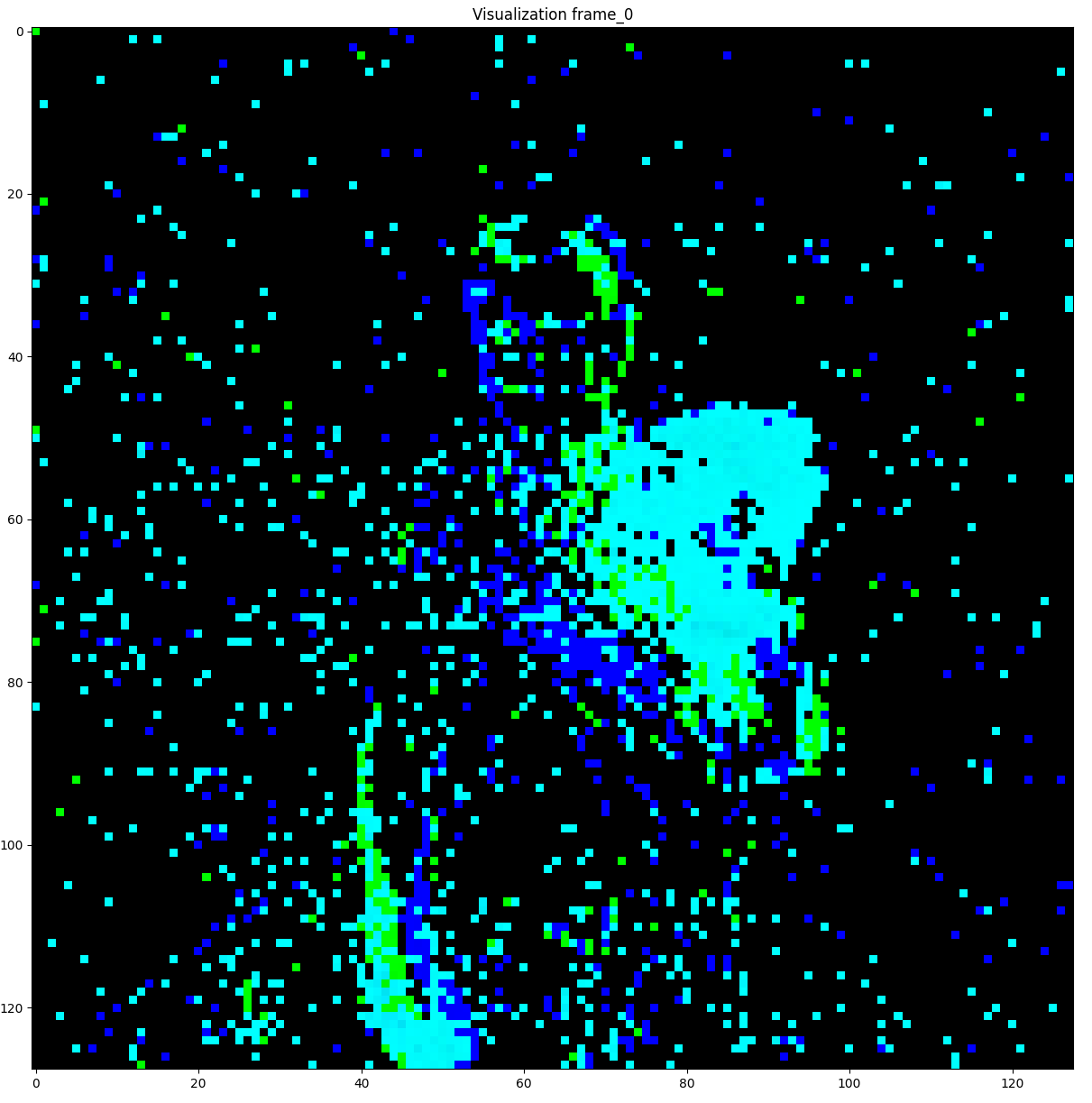
After implementing the concepts described above, I processed the training and test data. Although the visualization of frames was not required by my mentor, I decided to visualize them for fun and to verify if the frames were generated correctly. I wrote some visualization functions to transform the frames data into a GIF. Here is a visualization of a captured frame:
Conclusion
In this research project, I delved into the principles of Spiking Neural Networks (SNNs) for action recognition. Compared to traditional neural network models, SNNs are more technical and promising. Specifically, my study of the SNN dataset allowed me to understand a completely different form of data that is lighter than traditional datasets and therefore reduces the complexity of neural network computation. However, at present, this third-generation neural network model is not mature enough compared to traditional neural network models. Nevertheless, this is precisely why people continue to invest in this research.



